
![]()
|
|
Image
matching and Annotation Using Folksonomy |
|
|
|
![]()
1. Introduction
l
The amount of
user-generated images is increasing rapidly, thanks to easy-to-use multimedia
devices and cheap storage and bandwidth.
ž
As of November 2008, Flickr
is known to host three billion images.
ž
More than 700 million
photos are uploaded to Facebook each month as of January 2009.
l
Given the
ever-increasing amount of user-generated images, manually adding tags can be
considered infeasible.
ž
Time-consuming and
cumbersome.
ž
State-of-the-art
automatic image annotation techniques are still characterized by very low
precision.
l
Tag recommendation
can be seen as a trade-off between automatic image annotation techniques and
manual tagging.
ž
First, tag
recommendation assists in maintaining consistency between image and tags
ž
Second, automatically
suggesting tags makes it possible for users to annotate images in a more
time-efficient way. Users only have to select a number of proper tags among the
suggestions made.
l
In this research, we
propose a tag recommendation that exploits a visual folksonomy to produce more
meaningful tags for a query image.
ž
Our approach for
annotating user-generated images with a visual folksonomy allows the
exploitation of a rich and unrestricted concept vocabulary.
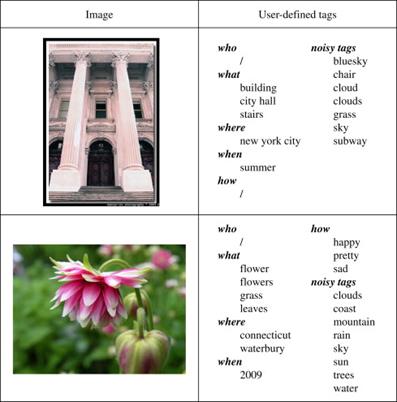
Fig. 1. User-contributed
images with user-defined tags.
2. Image Annotation Using a
Folksonomy

Fig. 1. Process of
image tag recommendation using Folksonomy.
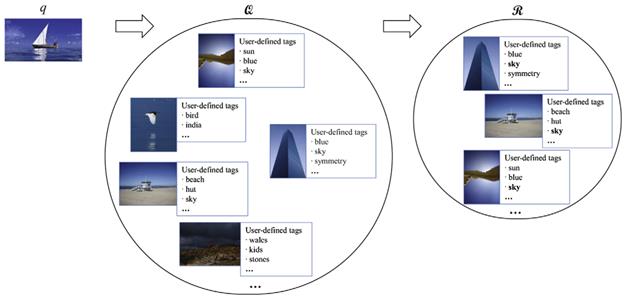
Fig. 2. Construction of the
restricted folksonomies Q and R. Recommended tag for the query image q is “sky”
in this example.
l
Tag recommendation
procedure:
ž
Step 1: construct Q
containing images that are visually similar to the input query image q.
ž
Step 2: construct R
by selecting a subset of images in Q that are related to a particular tag.
ž
Step 3: recommend
meaningful tags for q using the tag statistics.
<Experimental results>
l
@MIRFlickr-25000:
ž
25,000 images are
annotated with 223,537 tags assigned by 9,862 users
|
|
|
|
(a) |
(b) |
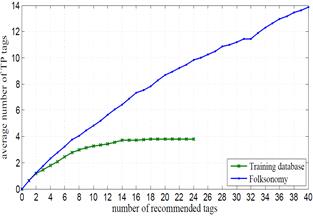

Fig. 3. Performance of the proposed tag
recommendation technique compared to a method using a training database with a
limited a limited number of concepts.
(a)
Average number of TP tags.
(b)
Average number of FP tags.
3. Leveraging a Folksonomy for
Semantic Feature
l
Observation: Image transformation
tends to preserve the presence of semantic features (see Fig. 4).
l
We take advantage of
the collective knowledge in an image folksonomy for unlimited semantic concept
detection (see Fig. 5).
ž
We make use of
visually similar images (to query image) retrieved from an image folksonomy
(see Fig. 6).

Fig. 4. Examples to
show that sematic features can be preserved in image transformation.
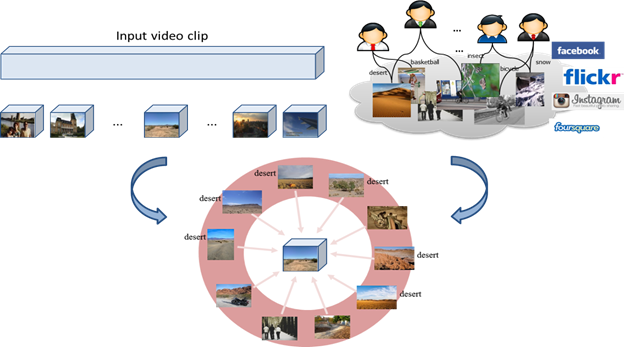
Fig. 5. Conceptual
illustration for video matching using semantic feature (i.e., visual
folksonomy).
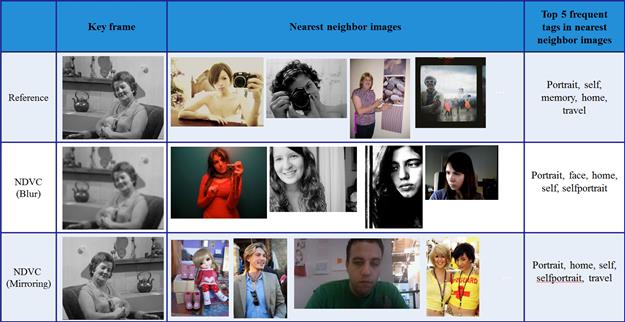
Fig. 6. Original and transformed key
frames of video, their nearest neighbor images, and top 5 frequent tags in the
nearest neighbor images.
<Experimental results>
l
Reference video and
query video set
ž
TRECVID 2009 set
ž
Size: 400 videos (100
hours)
l
Folksonomy
ž
Using the collective
knowledge in MIRFLICKR-25000
|
|
|
|
(a) |
(b) |

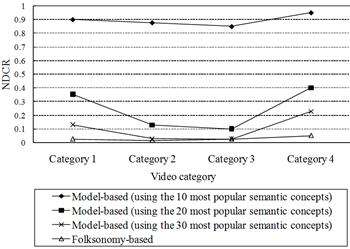
Fig. 7.
(a) Performance comparison under
different image transformations.
(b) Comparison between model based
approach and folksonomy based approach
![]()
* Contact Person: Prof. Yong Man Ro (ymro@ee.kaist.ac.kr)
![]()
1. Sihyoung Lee, Wesley De Neve, and Yong Man Ro, “Tag Refinement in an Image Folksonomy Using Visual Similarity and Tag Co-occurrence Statistics,” Signal Processing: Image Communication, 2010.
2. Sihyoung Lee, Wesley De Neve, Konstantinos N. Plataniotis, and Yong Man Ro, “MAP-based Image Tag Recommendation Using a Visual Folksonomy,” Pattern Recognition Letter, 2010.
3. Hyun-seok Min, Jae Young Choi, Wesley De Neve, and Yong Man Ro, “Near-Duplicate Video Clip Detection Using Model-Free Semantic Concept Detection and Adaptive Semantic Distance Measurement,” IEEE Transactions on Circuits and Systems for Video Technology (CSVT), 2011.
4. Hyun-seok Min, Jae Young Choi, Wesley De Neve, and Yong Man Ro, “Bimodal Fusion of Low-level Visual Features and High-level Semantic Features for Near-duplicate Video Clip Detection,” Signal Processing: Image Communication, 2011.
![]()