![]()

![]()
|
|
Face Detection for Low Power Event Detection in Intelligent Surveillance
System |
|
|
|
![]()
1. Introduction
l Recently, the
development of intelligent surveillance system increasingly requires low power
consumption.
l For the power saving,
this research presents an event detection function based on automatically
detected human faces, which adaptively convert from low power camera mode to
high performance camera mode.
l We propose an
efficient face detection (FD) method for operating under the low power camera
mode.
o Two-stage FD
structure: ROI selection and FP reduction.
o This requires a
very low computational complexity and memory requirements without sacrificing
the face detection robustness.
o Through the
hardware implementation, the proposed method is validated in the gate level
simulation.
2. Human Face based Event Detection for Intelligent
Surveillance System
l Event detection
function in order to reduce the power consumption
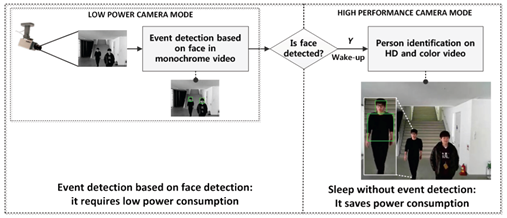
Fig. 1.
Operation scenario using the face based event detection two camera modes.
o Low power camera
mode (QVGA monochrome frames) is always turned on for continuously sensing
human intrusions while keeping power consumption low.
o High power
camera mode (HD color frames) wakes up when a face is detected by FD module.
(Conducting the object recognition)
l The use of the
two different camera modes is able to achieve significant power savings over
traditional video surveillance systems which use a single high performance
camera mode (HD color frames only).
3. Proposed Face Detection for Low Power Camera
l Proposed face
detector
o Minimum face
size: 16x16 pixels
o Input image:
QVGA (320x240 pixels) resolution, monochrome frame, and 4-bit quantized image
(for reducing the power dissipated in image sensor)
o Two-stage
structure (please see Fig. 2)
§ 1st stage:
ROI (to be scanned for face detection) selection
§ 2nd
stage: false positive (FP) reduction (only ROIs are examined)

Fig. 2. Overview of the proposed FD method for low power camera mode.
o The two stage
enables to speed up FD without using additional skin color information.
o The proposed FD
deals with very small sized faces (e.g., 16x16 pixels) due to a robust feature
extraction.
o In terms of SRAM
memory usage, the proposed FD itself requires very low power consumption.
l 1) First Stage:
ROI Selection
o Pre-filtering:
image mean and variance (facial structure filter), refer to the Fig. 3.
§ To speed up FD,
we reject scan windows that have too large spatial variances or too small
spatial variances compared to face. (standard deviation measurement)
§ We reject scan
windows that have different structure from face in which eye region is brighter
than the cheek region. (In Fig. 3(b), 8x3 pixels corresponding to eyes and 8x2
pixels corresponding to cheek and nose)

Fig. 3.
Computation example of face mean and variance. (a) windows for variance, (b)
windows for means.
o Feature
extraction: local block texture feature
§ Divide each
window region (16x16 pixels) to three blocks as shown in Fig. 4.
§ Each block
regions are separately represented by histogram feature vectors (less
susceptible to subtle rotation and translation in face representation).
§ Histogram based
feature: Local Binary Pattern (LBP) due to the following advantages
·
Low computational complexity
·
Invariance against monotonic illumination variation
§ The histograms
for each block (hL_eye,
hR_eye,
hmouth)
are obtained with the LBP parameters (P=4
and R=1), then concatenated (refer to
the Fig. 4.). The final histograms hSW is:
![]()
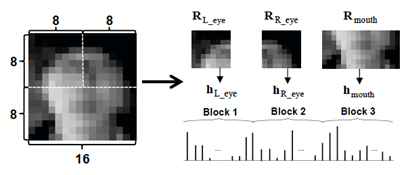
Fig. 4. Illustration of the block
texture feature extraction.
o Multiple feature
templates matching: L1-norm (Manhattan distance)
§ The total
histogram feature vector is compared to each feature template one by one.
§ The comparison
is repeated until the best-matched feature template is found.
§ When computing a
distance between templates and test, we use the L1-norm to reduce the
computational complexity in hardware.
§ If the L1-norm
distance is smaller than the pre-defined threshold, the scan window is
classified as a face candidate.
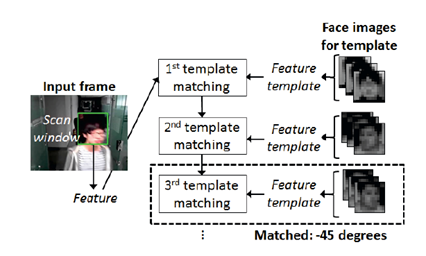
Fig. 5. Illustration of the proposed
multi-view face detection using feature templates matching.
l 2) Second Stage:
False Positive Reduction Using Strong Classifier
o As the strong
classifier, we adopt the linear support vector machine (SVM) due to its
robustness and high generalization capability.
o SVM learning by
the following quadratic optimization functions (where the kernel function in
linear SVM is an inner product):

o Using the
obtained SVM training model (i.e., support vectors, Lagrangian
multipliers (ai), and bias (b)),
the SVM confidence value h for hSW is computed by using the following equation:
![]()
o The weight
vector (w) can be defined by the
linear combination of support vectors with the Lagrangian
multipliers.
o We can see that
the computation of the SVM confidence value requires only one inner product
operation in the linear SVM.
o The scan window
is determined as a face if the confidence value is larger than the pre-defined
value, otherwise, it is determined as a non-face.
4. Experiments
l Database for
evaluation: Videos acquired by using a web camera (Microsoft LifeCam) and a
closed-circuit television (CCTV) camera (NCD-2000P)

Fig. 6. Example of video frames with the
results of the proposed method. (a) For V1 with occlusion between multiple
subjects. (b) For V2 with blurred and flashed face. (c) For V3 with shaded
face. (d) For V4 with tilted face by high camera angle.

Fig. 7. Example of video frames with the
results of the proposed method. (a) For V5 (including illumination variation).
(b) For V6 (including pose variation).
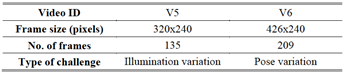
Table 1. Test videos used in the
experiments.
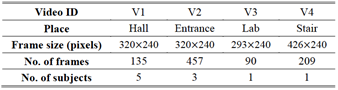
Table 2. Test videos used in the
experiments with different type of challenges.
l The FD uses
sliding window based detection based on down-sampling, where the
nearest-neighbor interpolation is used with the scale factor 1.4. The window
shift for scanning is 2 pixels. The detection results overlapped at a location
are merged to form a final detection.
l Feature
templates construction
o We collected 64
face images of various styles, which were not present in the test video.
o To deal with
variation in facial pose, we considered the three different poses, i.e.,
frontal, ‘+45 degree in yaw’, and ‘-45 degree in yaw’.
o In each pose,
the block texture feature was extracted from every face image.
l SVM Training
using LIBSVM library
o We collected the
face and non-face images from random images in web, video frames captured by
the web camera, and images from the public face databases (e.g., FERET DB).
o For training,
1,084 images for face samples, and 7,120 images for non-face samples
l For the comparative
evaluation, we presented the two existing well-known FD methods
o Viola-Jones face
detector (adaptive boosting with Haar-like features)
using OpenCV
o Adaptive
boosting (AdaBoost) based on LBP feature (LBP+AdaBoost) using OpenCV
l 1) Face
Detection Performance Evaluation
o For test, the
subjects move towards camera (where the videos contained very challenging
frames with occlusion, blurring, highlighting, head tilting, etc.)
o According to
Table 3, the proposed FD outperforms the other two methods.
Table 3. Experimental results for V1-V4.
(a) For faces larger than 24x24 pixels. (b) For faces larger than 16x16 pixels.
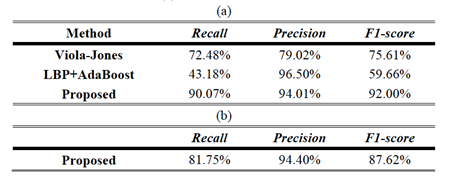
o To examine the
robustness of the proposed FD method to illumination variations and pose
variations, we performed FD on the V5 and V6.
o Illumination
variations: ranging from 5 lux to 250 lux with camera exposure value set to
‘-8’ (refer to Table 4.)
§ The proposed FD
outperforms Viola-Jones method.
§ This stems from
the face of the relative robustness of texture feature to illumination
variation than Haar-like feature.
o Pose variations:
ranging from +60 degree (looking at right) to -60 degree (looking at left)
(refer to Table 5.)
§ The proposed FD
is also robust to pose variation due to the use of multiple templates.
Table 4. Experimental result for V5 with
illumination variation.

Table 5. Experimental result for V6 with
pose variation.

l 2) Face
Detection Simulation for Hardware Implementation
o Most of power
consumptions in a digital system are directly affected by memory usage, i.e.,
data transfer and storing a large amount of data in a memory.
o In order to
reduce memory usage, our designed FD system optimizes the system architecture
and reduces the number of required gate counts.
o In particular,
the image scaling (for down-sampling) for obtaining multi-scale images for the
FD task is implemented by a line memory (SRAM) based design unlike the previous
implementations based on a frame memory (DRAM).
§ It can
considerably reduce the number of gate counts for low power consumption.
o In addition, our
FD system can process all of scaled data simultaneously through merging line
memories for each scaled image.
o Moreover, to
increase the speed of the operation and parallelism, our FD system uses a
pipelined structure for the block texture feature extraction, and the
computations of the mean and the variance used in the pre-filtering.
o To verify the
effectiveness of the hardware implementation of the proposed FD method, the
designed FD system was evaluated by gate level simulation using DongBu 0.11um cell library.
§ This system can
be implemented with 83K gates.
§ In particular,
only 7K gates are required for generating a 320x240 pixels image scaled pyramid.
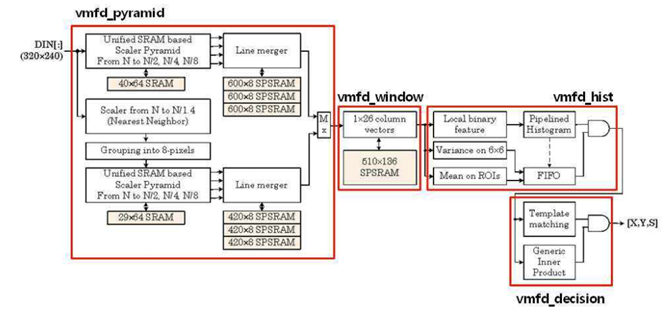
Fig. 8. Overall block
diagram of the implemented hardware architecture.
|
* Contact Person: Prof. Yong Man Ro (ymro@kaist.ac.kr) |
|
|
![]()
1. Hyung-Il Kim, Seung Ho Lee, Jung Ik Moon, Hyun-Sang Park, and Yong Man Ro, “Face Detection for Low Power Event Detection in Intelligent Surveillance System,” IEEE International Conference on Digital Signal Processing (DSP), Hong Kong, 2014.
![]()
ü Video1: Face Detection with GUI that can control parameters; 1) template matching threshold, 2) FP reduction (SVM confidence value), and 3) merging parameters in video.
o Note that
§ White box: windows passed by 1st stage
§ Red box: windows passed by 2nd stage
§
Green circle: final decision by
merging candidates (our FD returns the position of face candidate as an event
detector.)
ü Video2: Face detection result,
where the left upper corner ‘x.x m’ means the first
detected distance from a camera and the green box is the detected face with the
size of face.