|
1. Introduction
Currently, ISO/IEC MPEG and ITU-T VCEG are jointly
making a scalable video codec (SVC) standard that is based on the
H.264/AVC. The objective of SVC is to generate temporal, spatial, and SNR
scalable coded stream, which provides users with QoS (Quality of Service)
guaranteed streaming independent of video consuming devices in
heterogeneous network environments. Layered codec structure, Hierarchical
B picture prediction, and FGS (Fine Granular Scale) coding scheme are
employed for the spatial, temporal, and SNR scalability.
However, SVC sacrifices coding efficiency to enable
the scalability. One of the reasons for lowering coding efficiency is the
layered coding structure for the spatial scalability. The layered coding
approach adopted in SVC is similar to MPEG-2, H.263 and MPEG-4 visual.
The video with lowest resolution is encoded in the base layer, and the
video with a higher resolution is encoded in the next layer, which
results in inter-layer redundancy. In order to reduce the redundancy due
to the layered structure, inter-layer prediction for motion and
texture/residual are used in SVC. The motion, texture and residual of
lower resolution are upsampled, and used as the predictions. By using
these inter-layer predictions, the coding efficiency of SVC is increased.
But encoding with multi-layer configuration still shows less coding
efficiency than that with single layer configuration, which means that
there still exists inter-layer redundancy even with current inter-layer
coding scheme in SVC.
Recently, adoptive motion refinement that performs motion
estimation/ compensation in the FGS layer has been proposed to enhance
the performance of FGS codec, and it is adopted as an optional encoding
scheme in SVC. If adoptive motion refinement is enabled in FGS, motion
based inter-frame coding is performed with newly estimated motion data in
the FGS codec. With the adoptive motion refinement, motion is estimated
according to the bitrate of its FGS layer, and the motion information
could be a new candidate for the inter-layer motion prediction in addition
to the motion information in the base quality layer.
In our research, we propose improved inter-layer
motion prediction with adoptive motion refinement.
2. Inter-layer Prediction with Adoptive Motion Refinement
in Scalable Video Coding
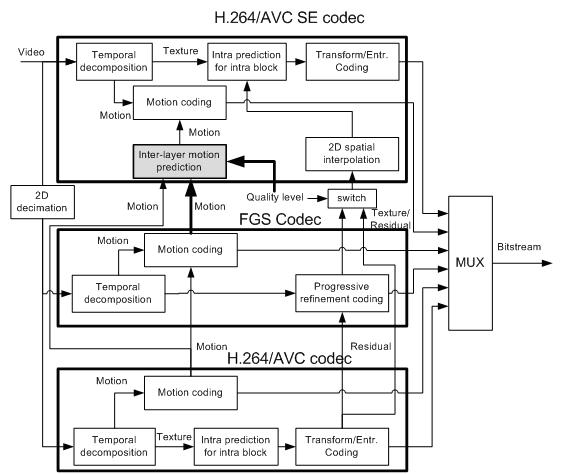
Figure 1 shows the structure of SVC with the
proposed inter-layer motion prediction when two spatial resolution video
is encoded and SNR scalability is supported by FGS layer in the base
layer. Inter-layer motion prediction is performed in the shaded block in
Figure 1. The bold lines in Figure 1 indicate new information inputted to
the inter-layer motion prediction for the proposed method. With the
adoptive motion refinement, each FGS layer has its own motion
information, thus the motion information in FGS layers is newly inputted
to the inter-layer prediction. Because it is necessary to select a SNR
layer for inter-layer motion prediction, quality level is also needed in
the inter-layer motion prediction.
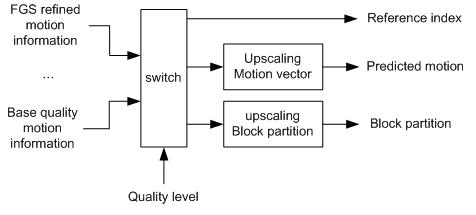
The shaded block in Figure 1 is depicted in detail in
Figure 2, where the proposed inter-layer motion prediction with refined
motion of FGS layer is performed. The motion information of each SNR
layer is inputted into inter-layer prediction module. The motion
information includes motion vector, reference index, and macroblock
partition, and that of the layer selected by quality level is used for
the inter-layer prediction. The processing of each element of motion
information is as follows. The macroblock partition of the selected layer
is scaled according to the resolution ratio between the base and the
enhancement layers, and the reference indexes of selected layer are
directly used in the enhancement layer. The motion vectors of the
selected layer are upscaled according to the resolution ratio between the
enhancement and the base layer. Then, in the motion coding module in
Figure 1, the quarter-sample motion vector refinement is searched with
the predicted motion vector. The cost of the inter-layer motion
prediction is compared with those of the other block modes, and the mode
that has minimum cost is used for macroblock encoding.
Inter-layer motion prediction is also performed in the
decoder, and as shown in Figure 2, no additional computational processing
is required in the decoder except selecting motion information among base
and FGS layers in the lower resolution layer.
|
|
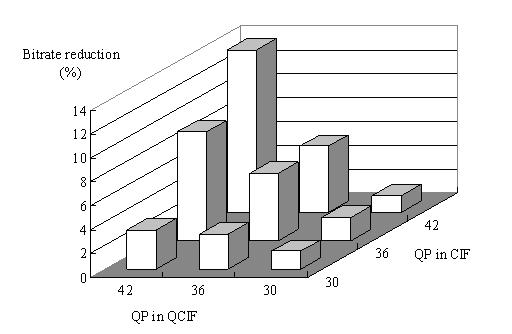
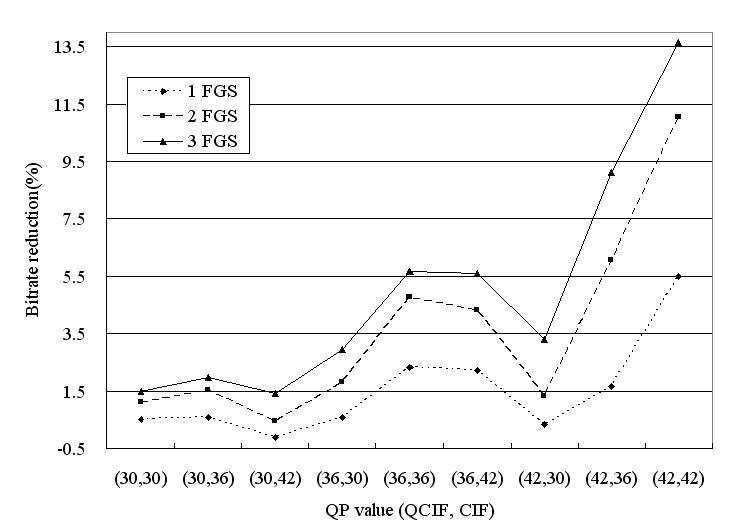
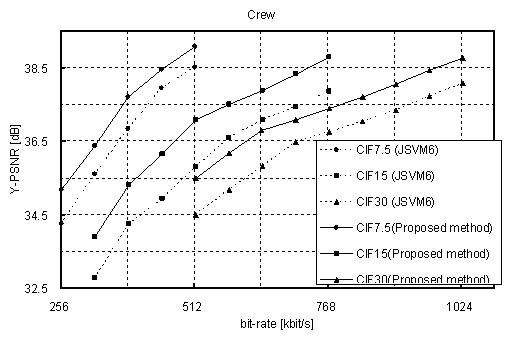
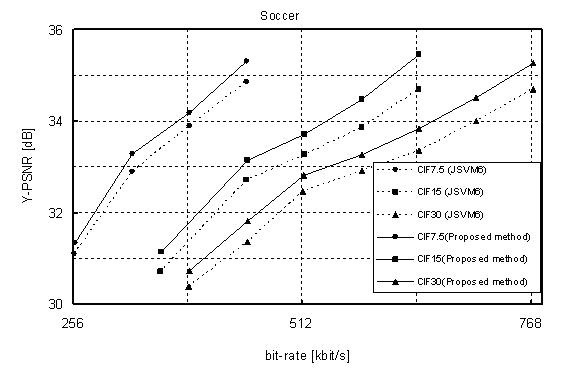
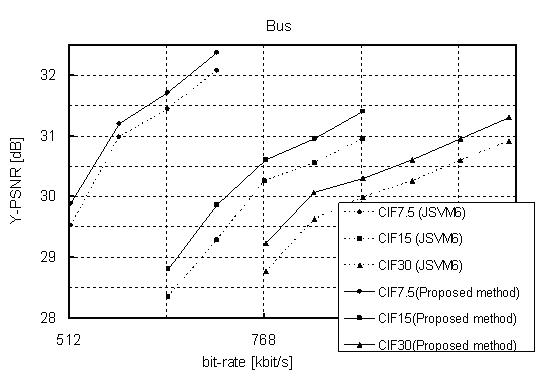
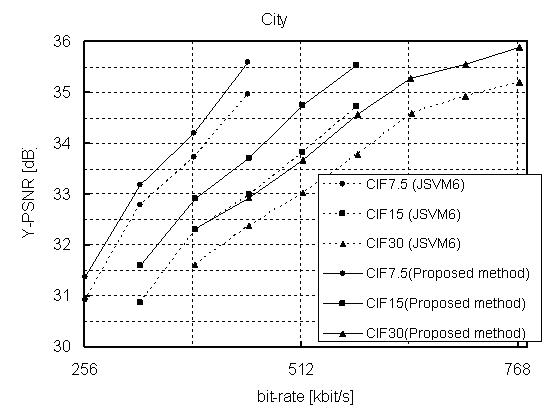
3. Experimental Results
The proposed
method was implemented in JSVM (Joint Scalable Video Model) 6 that is
software model of SVC. The following SVC test sequences are used for the
experiment: “Bus,” “Soccer,” “Crew,” and “City.” We measured the bitrate
savings of the bitstreams provided by our approach with respect to the
bitstreams provided by JSVM 6. In the experiment, A two layer
configuration—{QCIF, 15 fps (frame per second)}, {CIF, 30fps}—is used for
encoding the sequences, and QCIF layer has three FGS layers with enabling
adoptive motion refinement. The GOP (Group of Picture) size is set to 16,
and quality level that is used for inter-layer prediction in CIF layer is
set to the highest FGS layer of QCIF.
|