|
 
|
|
|

|
|
|
|

|
Real-time Video
Information Retrieval and Environment Invariant User Gesture Recognition Algorithm
Development
|
|
|

|
2008 . 08 ~ Current
|
|
|
|

|
|
|
|
1. Introduction
In the Human Robot
Interaction (HRI), it is required for intelligent robots to recognize the
outer state, and make decisions in order to successfully interact with humans.
Therefore it is necessary to carry out user detection in the real time
process for an effective HRI. To carry out user detection in the real
time process, partial decoding and compression domain approach is
performed. The extracted visual information will be used to detect face, torso and hand as well as tracking of those user
body parts will allow successful user detection and recognition.
The
purpose of this project is to detect face, torso and hand of user as well
as to recognize the user movements and gestures by using the compressed
video produced by the embedded robot. After robot acquires the visual
information, it uses compressed format such as MPEG to send the
information to the server through network. To save computation load as
well as the cost of bandwidth, the compressed domain approach is
necessary. The specific goals of this project are as follows.
1)Extracting visual
information required for user detection in real-time from the MPEG
Compressed domain
2)Developing environment
invariant face detection and tracking algorithm, that is illumination and
other characteristics of robot are considered
3)Developing gesture
recognition with the tracked object information
2. Robot vision system
Since the embedded robot uses server to perform user detection processing, this is a client/server based architecture known as network robot.
The robot perceives visual information through two cameras. Then it
compresses the information using MPEG-4 encoder then sends it to the
server through USB/Ethernet. When images are received, stereo image is
created to provide additional information.
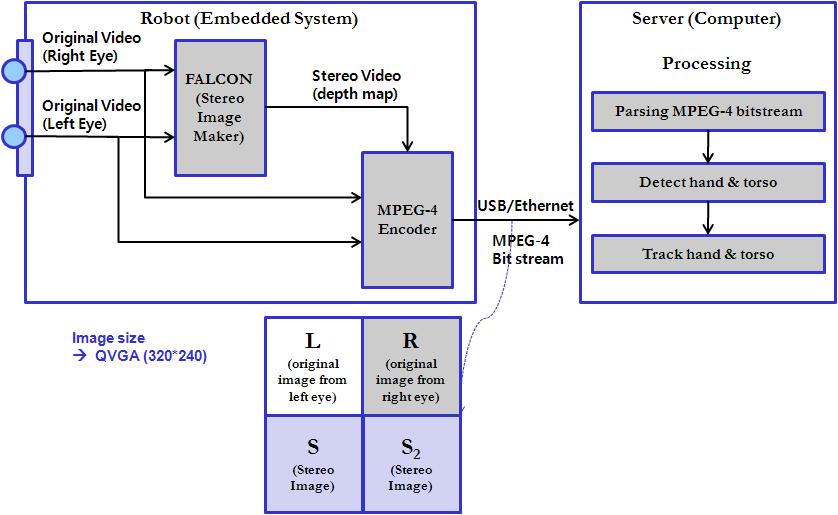
The following diagram shows the overall robot vision system and the processing part in the server.
|
|
|
|
Fig. 1. The robot
vision system
|
|
As shown in figure 1, the robot
vision system consists of the embedded robot, USB/Ethernet (Network) and
the server. The embedded robot mainly perceives images through two cameras,
and forms two stereo images that can be used later. Also, These images
are compressed using MPEG-4 compression, and transmitted to the server
using USB/Ethernet. In the server side, the bitstream
analyzer is used to extract necessary information and proceeds to
detection and tracking module.
|
|
|
|
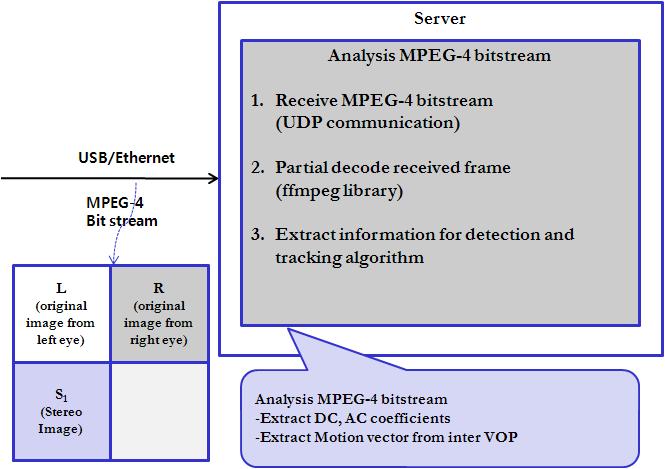
Fig. 2. MPEG-4 bitstream
Analyzer
|
|
The bitstream analyzer has three
functions to carry out as seen in Fig 2. It receives MPEG-4 bitstream produced by the robot in UDP communication protocols.
Then it uses FFMPEG library to partially decode received frame. Then
extracted DCT parameters and Motion vectors are later used for user
detection and tracking.
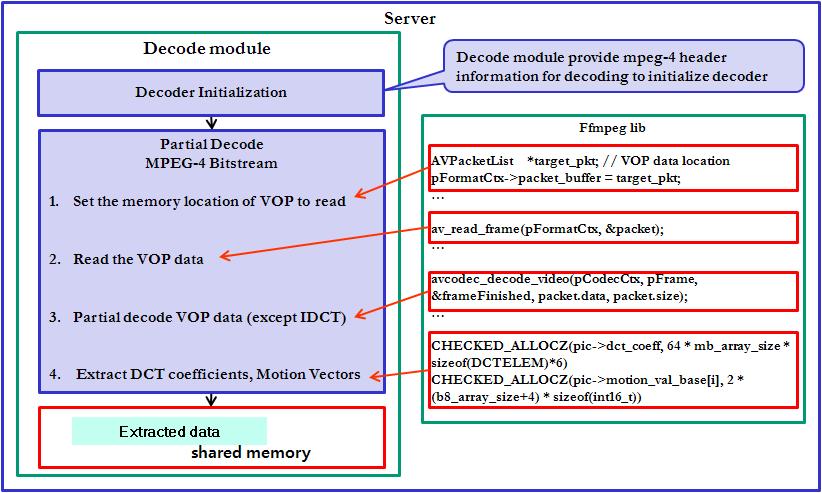
Fig 3. illustrates the detailed
decoding module. The project uses FFMPEG library as mentioned for
decoding bitstream. The MPEG-4 header
information to be parsed is generated. The system header including image
resolution, codec information, GoP size as well
as visual data from the embedded system. Also, the system uses memory
management to store MPEG-4 frame for real-time processing. The same
memory location is allocated for every delivered frame. After storing one
frame data, they are also sent to ffmpeg
directly in real-time. A length of MPEG-4 data is unfixed as it is with
the memory too.
|
|
|
|
Fig. 3. Decoding module using FFMPEG library
3. User Detection
|
|
Once, the necessary information
is extracted, the user detection is performed by first taking face
detection process. Since user detection requires face information to
start with, face is first detected from the given information. The DC
coefficients extracted from the above procedure will be used to form a DC
image, which will be used as an input for the face detection system that
works directly under the compressed domain as well as invariant to other
environmental factors including illuminations and camera characteristics.
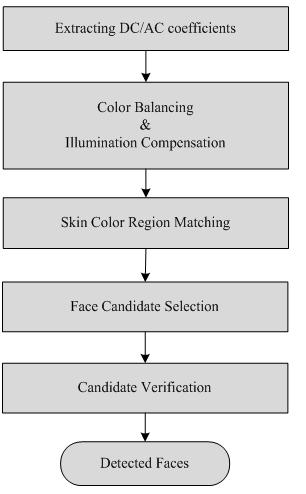
The overview of the face detection system is as follows.
|
|
|
|
Fig. 4. Overview of the face detection system
|
|
|
When DC image is formed, it requires consistent characteristics
and illumination compensated information for reliable face detection
results, hence, color balancing and illumination compensation are
performed. Color Balancing is performed using the color temperature
conversion. Color temperature conversion is performed by using the MPEG-7
descriptor. Basically, temperature of the DC image is estimated using CIE
1960 UCS diagram, and converted to target temperature using Bradford
chromatic adaptation. The target temperature is set to 5500K by taking into
consideration the daylight and under electronic lights which have
temperature of 5500K. This would allow consistent characteristics for all
robot cameras, since different information is obtained with the same
objects. Then, illumination compensation is performed to provide reliable
face detection. Often illumination factors are significant in color based
face detection approach, since it corrupts skin color information.
Therefore, illuminations must be compensated, and in this project, Retinex algorithm was employed to eliminate
illumination components. Retinex algorithm is
based on the human visual system proposed by Land, which effectively
eliminates illuminations by leaving reflectance components only in the
image. Then reliable skin colors can be detected for the next steps. Once
skin color region is matched by using proven skin color model, the face
template is used to match against any skin color region. If there is a
match, the region is selected as face candidate region. The face candidate
regions must be verified using two properties of face: 1) All face has
details and edge information 2) All face has more
intensity change in the direction of vertical rather than horizontal. These
two properties can be used by calculating the energy distributed in that
face candidate region. To do so, AC coefficients extracted earlier with the
DC coefficients, are used for this energy calculation. Finally, if the
criteria are met, then the candidate region is finally known as face
region.
|
|

|
|
Fig. 5. Torso mask and Torso detection results
With the acquired face
region information, torso region can be decided. In addition, stereo image can
be used to verify the position of the torso. The torso mask used in this
project is based on Virtuvian torso, which states
that the torso has the twice size of the face. Therefore, when face
information is used torso can be predicted. Also, stereo image
distinguishes foreground and background where foreground can be used to
verify that the torso is taking place. The fig. 5 shows the torso mask and
the results of torso detection and face detection.
Then hand region can be
easily detected. Because hand also contains skin color information, any
skin color region rejected by the face candidate, can be used to predict
the hand. However, there may be an error or noise, therefore in order to be
sure about the hand, it requires certain
amount of skin color regions beside the predicted region due to the fact,
hand also takes portion in the image. The following figure is the results
of hand detection. and it concludes the user
detection module.
|
|
|
|
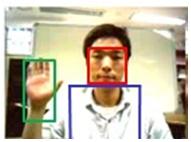
|
|
Fig.6. The detected face, torso and hand of the user
|
|
3. User Tracking
The user tracking can be
performed when user detection has been accomplished. The detection takes in
I frame, therefore in P frames, tracking will be performed with the motion
vector extracted before, and each detected regions. The following
diagram clearifys the Intra VOP and Inter VOP
detection and tracking.
|
|
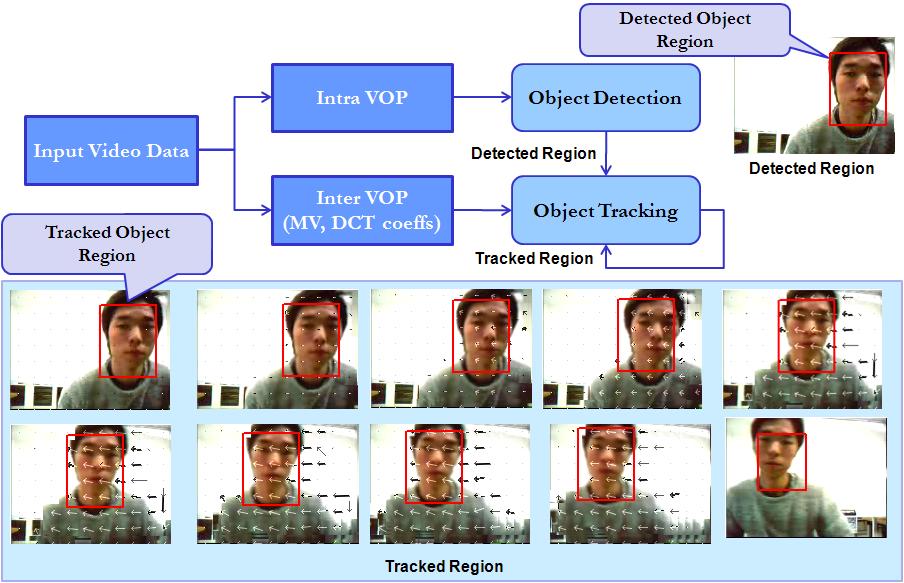
|
|
Fig.7. Tracking module for face region
|
|
The above example shows the tracking of the face region. Likewise, the region of interest (face, torso or hand) is passed onto the tracking module.
To be more specific, the object
tracking is performed as follows.
|
|
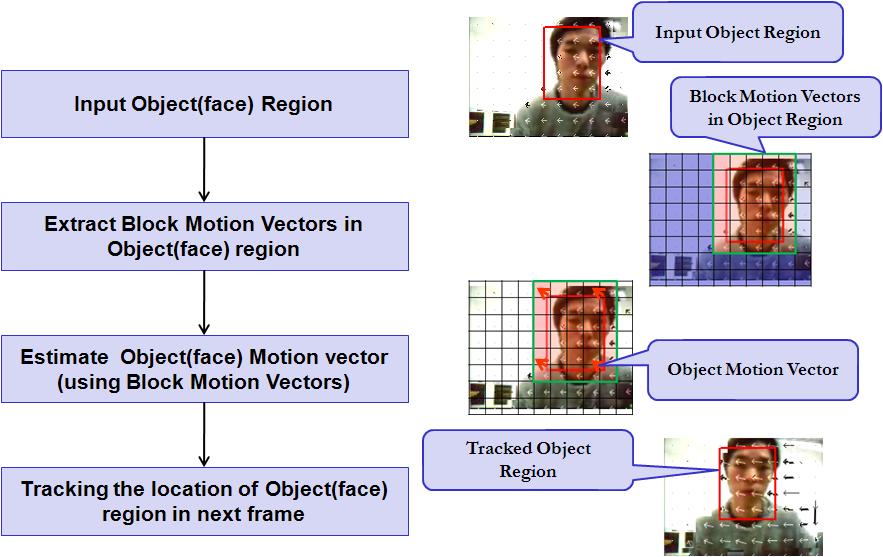
|
|
Fig. 8. Specific description of tracking
|
|
User detection and tracking is peformed as mentioned above. And user recognition using
detected information will be carried out by analyzing the coordinates of
the hand, elbow and other body parts based on the face, torso information.
This is currently under research.
|
|
|

|
|
|
|
*
Contact Person: Prof. Yong Man Ro (ymro@kaist.ac.kr)
|
|
|

|
|
|
|

|
“Design of Object Detection System in Video Compressed
Domain for An Intelligent Robot System,” Hyun-Seok
Min, Young Bok Lee, Yong Man Ro, TriSAI 2008,
Oct.6~9, 2008, DaeJeon, Korea
|
|
|
“압축 영역에서의 효율적인 얼굴 검출을 위한 조명 효과 개선에 관한 연구”, 이영복, 민현석 노용만, 2008 대한전자공학회 추계학술대회, pp.677-688, 연세대학교, November 29, 2008
|
|
|
"압축 영역에서 동작하는 조명 환경 변화에 강인한 얼굴 검출 방법에 관한 연구", 민현석, 이영복, 노용만, 2008 HCI 학술대회 (submitted)
|
|
|
|
|
|
|
|
|
|