
![]()
|
|
Video
Face Recognition Based on Face Quality Measure and Face Feature Fusion for
CCTV Surveillance System |
|
|
|
![]()
1. Introduction
l Recently, video face
recognition (FR) has received a significant interest, due to a wide range of
applications
ž Video surveillance, biometric identification,
and content-based video indexing/search.
l Compared to the number of
algorithms that do FR from stills, the research on video-based methods is
relatively small.
l Compared to a still image, a
set of face images can provide rich information discriminative for FR in the
face image set (see Fig. 1).
l Face image set may contain
large view-point (pose) and illumination changes and unuseful
face images such as blurred face images or mis-aligned
face images (see Fig. 2). These challenges could significantly degrade FR
performance.

Fig. 1. Examples
of face image sequence from videos.
|
|
|
|
|
(a) |
(b) |
(c) |
|
|
|
|
|
(d) |
(e) |
|





Fig. 2. Challenges of FR in face image set: (a)
Pose variation (rotation in yaw) (b) Pose variation (rotation in pitch)
(c) Expression variation (d) Illumination variation (e) Mis-aligned
faces.
l In this research, we propose a
new video FR method based on weighted feature fusion approach.
l The proposed method aims at
significantly improving FR accuracy by adaptively fusing the features extracted
from the multiple face images.
ž We develop a novel weight
determination solution for the purpose of attaining the best FR accuracy within
our weighted-feature-fusion-based FR framework.
ž In order to guarantee adaptive
nature in determining weights, fuzzy membership function and quality
measurement for face images can be used to compute weights of face features to
be combined.
2. Proposed Video FR method
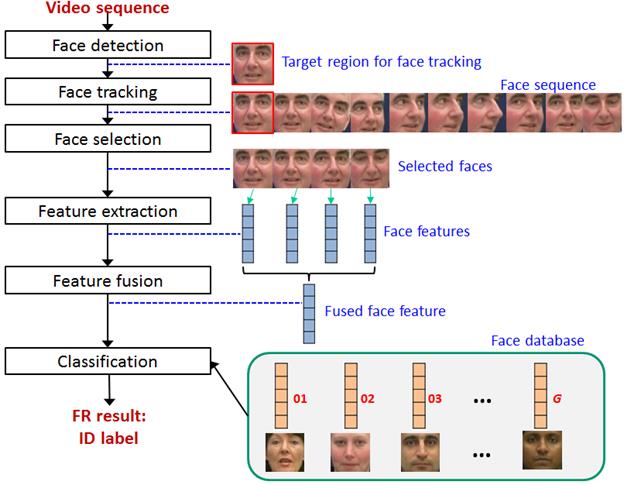
Fig. 3. Overall procedure of the feature fusion
based video FR.
l Let ![]() be a face sequence consisting of M face images
(obtained from a video sequence) with a single and be a same identity.
be a face sequence consisting of M face images
(obtained from a video sequence) with a single and be a same identity.
l In a typical video FR, the
face features of testing images are to be extracted and to be used for a
classification purpose.
l Herein, face feature of ![]() is denoted by
is denoted by ![]() . A combined face feature
generated using our weighted feature fusion is defined as
. A combined face feature
generated using our weighted feature fusion is defined as
|
|
(1) |
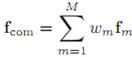

ž ![]() : the
weight value of
: the
weight value of ![]() .
.
l As shown in Fig. 3, given a
face sequence from video frames, the proposed weight determination method
largely consists of three sequential steps:
ž
Face rejection
ž
Selection of prototype face images
ž
Computation of weights using fuzzy membership function
2.1. Face
Rejection
l In practice, a number of mis-aligned face images may be present in a face sequence due
to incorrect face detection and tracking result.
ž Mis-aligned face images:
incorrectly rotated or scaled face images
ž Mis-aligned face images can
significantly degrade FR performance
l As such, mis-aligned
face images need to be filtered out.
ž For that purpose, an SVM
classifier is adopted to discriminate mis-aligned
face images from well-aligned face images.
l We can select mis-aligned face images by identifying face images assigned
negative confidence scores as outputs of an SVM classifier.
2.2.
Selection of Prototype Face Images
l In the proposed method, the
so-called prototype face images are defined as face images with frontal
lighting and small deviation from frontal pose, as well as with high sharpness.
1) Measurement of Facial Symmetry:
ü
We assess quality degradations caused by nonfrontal lighting and inadequate facial pose (especially
arising from out-of-plane rotation).
ü
The less left-right symmetric of the face image has
larger distance value between the left and right half regions, and has lower
image quality value.
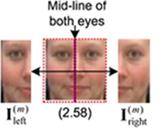

Fig. 4. Illustration of dividing a face
image (based on the midline of both eyes) into the left and right half regions
each denoted by ![]() and
and ![]() . Note that the text enclosed
in bracket below each facial image represents the value of differences between
pixel values of
. Note that the text enclosed
in bracket below each facial image represents the value of differences between
pixel values of ![]() and
and ![]() at the corresponding left-right pixel
locations.
at the corresponding left-right pixel
locations.
1) Measurement of Face Frontal-Pose Degree:
ü
For the case of face images with variation in pose
caused tilt, the facial symmetry measure may not correctly represent the
drifting away from frontal pose caused by tilt.
ü
To overcome this limitation, we develop a so-called
frontal-pose subspace based on the view-based reconstruction.
ü
The frontal-pose subspace model was constructed using
a data set including only frontal-pose face images.
ü
The quality score for frontal-pose degree is computed
as a residual reconstruction error between a test face image and its
reconstruction.

Fig. 5. Some examples of face images
used to validate the reliability of frontal-pose degree measurement.
2) Measurement of Face Image Sharpness:
ü
To assess the quality of facial images with respect to
blurring, we make use of the “Kurtosis” measurement.
ü
This approach computes the energy of the
high-frequency content of an image based on the statistical analysis of the
Fourier transform of the image for the purpose of measuring image sharpness.
l
Using all the scores of the three different quality
measurements, overall quality score of each face image is obtained by utilizing
a weighted sum of the scores of the three individual quality measurements.
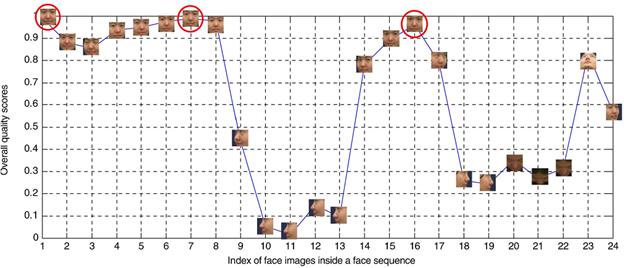
Fig. 6. Overall quality scores of
face images in a face sequence, computed using the
proposed quality measure. Note that the three face images that correspond to the
three prototype face images with highest scores are annotated by circles.
2.3.
Weight Computation Using Fuzzy Membership Function
l The proposed weight
determination solution takes advantage of the fuzzy membership function based
on the similarity view theory where membership is a notion of being similar to
prototype of the category.
l Membership function measures
the degree of similarity of all element face images of a given face sequence to
the associated prototype face images.
l Notations
ž
![]() : the
face sequence (outputted by a face rejection module) can be considered to be a
fuzzy set.
: the
face sequence (outputted by a face rejection module) can be considered to be a
fuzzy set.
ž ![]() : a
set of K prototype face images selected by using the method in Section 2.2
where
: a
set of K prototype face images selected by using the method in Section 2.2
where ![]() .
.
ž ![]() : a
set of face features each corresponding to the nth prototype face image.
: a
set of face features each corresponding to the nth prototype face image.
l Given the face features ![]() and
and ![]() of
of ![]() and
and ![]() , respectively, the distance
metric (Minkowski metric) is used to measure the
distance:
, respectively, the distance
metric (Minkowski metric) is used to measure the
distance:
|
|
(2) |
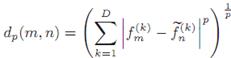
ž
![]() : the
kth element of the feature vector
: the
kth element of the feature vector ![]() and
and ![]() is the dimension of the feature vectors.
is the dimension of the feature vectors.
l
For the ![]() , the sum of distances with
all the selected prototype features is the distance criterion:
, the sum of distances with
all the selected prototype features is the distance criterion:
|
|
(3) |
ž
K: the number of prototype face
images selected.
l
The membership value for the ![]() is determined as follows:
is determined as follows:
|
|
(4) |
ž
where ![]() and
and ![]() are parameters to be determined.
are parameters to be determined.
ž
The value of ![]() is used to adjust the weighting effect of
the membership function, and
is used to adjust the weighting effect of
the membership function, and ![]() is a weight scale threshold.
is a weight scale threshold.
l
The weight to be assigned to each image ![]() within a face sequence is computed as
follows:
within a face sequence is computed as
follows:
|
|
(5) |

ž
![]() and
and ![]()
l
The results in Fig. 7 validate the effectiveness of
the proposed method for determining weights.
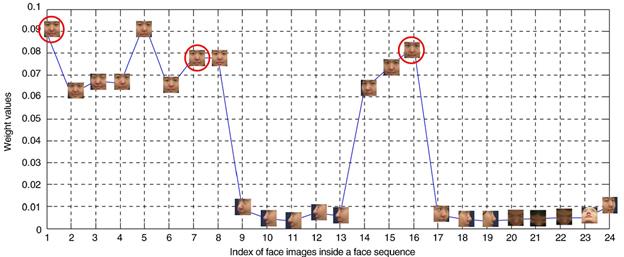
Fig. 7. Weight values computed for
each face image within a face sequence to show the effectiveness of determining
weights using the proposed method. Note that the three face images that correspond
to the three prototype face images with highest overall quality scores are
annotated by circles.
3. Experiment
<Experimental setup>
l
Used video face DBs: the VidTIMIT,
YouTube celebrity, Honda/UCSD, and CMU MoBo.
l
The Viola-Jones face detection and the Lucas-Kanade face tracking techniques were run on all video
frames.
l
The detected and tracked face images were rescaled to
44 x 44 pixels (refer to Fig. 8).
l
Three popular feature extraction techniques were used
to construct feature extractors for computing face features:
ž
Fisher’s linear discriminant analysis (FLDA)
ž
Regularized linear discriminant analysis (RLDA)
ž
Eigenfeature regularization and extraction (ERE). In
addition
l
Gabor wavelet face representation was used in
conjunction with the aforementioned low-dimensional feature extraction
techniques.
|
|
|
|
(a) |
(b) |
|
|
|
|
(c) |
(d) |




Fig. 8. Example of face sequences used in our experiments,
which show a variety of different lighting, pose and occlusion conditions, and
misaligned face images. (a) VidTIMIT DB. (b) YouTube
celebrity DB. (C) Honda/UCSD DB. (d) CMU MoBo DB.
3.1.
Results on VidTIMIT Data set and YouTube Celebrity
Data set
<Comparison methods>
l Baseline: A conventional
still-image-based FR solution (only using a single face image)
l FR using majority vote:
Integrates the recognition result in each frame using majority voting
l Proposed (uniform weighting):
all face features have the same weights
l Proposed (fuzzy weighting):
weights are determined using fuzzy membership function
Table 1. Effectiveness of the proposed method on the VidTIMIT
DB. “K” represents the number of selected prototype face images.

Table 2. Effectiveness of the proposed method on the YouTube celebrity DB.

<Results>
l Compared to baseline method,
the rank-one identification rate can be substantially improved with around 40%
for all feature extraction methods.
l The proposed fuzzy weighting scheme
considerably outperforms the approach using uniform weights.
ž This demonstrates the
effectiveness of the proposed weight determination solution in terms of
achieving the best possible recognition accuracy via the proposed weighted
feature fusion method.
l The proposed method can
achieve the FR performance of up to about 91% for YouTube celebrity DB.
ž This results show that the
proposed method can achieve acceptable recognition accuracy over challenging
and real-life face images.
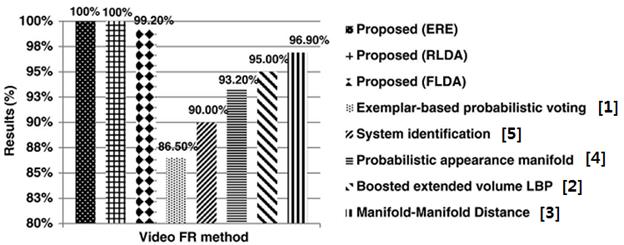
3.2.
Comparisons with other video FR methods

<References for comparison methods>
[1] A. Hamid and M. Pietikainen, “From still image
to video-based face recognition: An experimental analysis,” in Proc, IEEE Int. Conf. AFGR 2004.
[2] A. Hamid and M. Pietikainen,
“Combining appearance and motion for face and gender recognition from videos,”
Pattern Recognition, 2009.
[3] R. Wang, S. Shan, X. Chen, and W. Gao,
“Manifold-manifold distance with application to face recognition based on image
set,” in proc. IEEE Int. Conf. CVPR, 2008.
[4] K. C. Lee, J. Ho, M. H. Yang, and D. Kriegman,
“Video-based face recognition using probabilistic appearance manifolds,” in
Proc. IEEE Int. Conf. CVPR, 2003.
[5] G. Aggarwal, A. K. Roy-Chowdhury, and R. Chellapa, “A system identification approach for video-based
face recognition,” in Proc. IEEE ICPR 2004.
![]()
* Contact Person: Prof. Yong Man Ro (ymro@kaist.ac.kr)
![]()
1. J. Y. Choi, K. N. Plataniotis, and Y. M. Ro, “Face Feature Weighted Fusion Based Fuzzy Membership Degree for Video Face Recognition,” IEEE Transactions on Systems, Man, and Cybernetics-Part B, 2012.
2. J. Y. Choi, W. D. Neve, Y. M. Ro, and K. N. Plataniotis, “Automatic Face Annotation in Personal Photo Collections Using Context-Based Unsupervised Clustering and Face Information Fusion,” IEEE Transactions on Circuits and Systems for Video Technology, 2011.
3. J. Y. Choi, W. D. Neve, and Y. M. Ro, “Towards an Automatic Face Indexing System for Actor-based Video Services in an IPTV Environment,” IEEE Transactions on Consumer Electronics, 2010.
![]()
l Video1: Real-time face
detection and recognition in CCTV video.
l Video2: Effectiveness of
fusing multiple face features for FR.